
近年目まぐるしい進化を遂げる生成AI。ビジネスでも多くのメリットをもたらす一方、生成AIが不正確な回答や誤った情報を生成してしまう現象は「ハルシネーション(幻覚)」として問題視されています。そうしたなか、この課題を解決する手法として注目を集めているのが、RAG(検索拡張生成)です。本記事では、RAGの基本的な仕組みや生成AIとの違い、具体的な活用事例などを詳しく解説します。
RAGとは
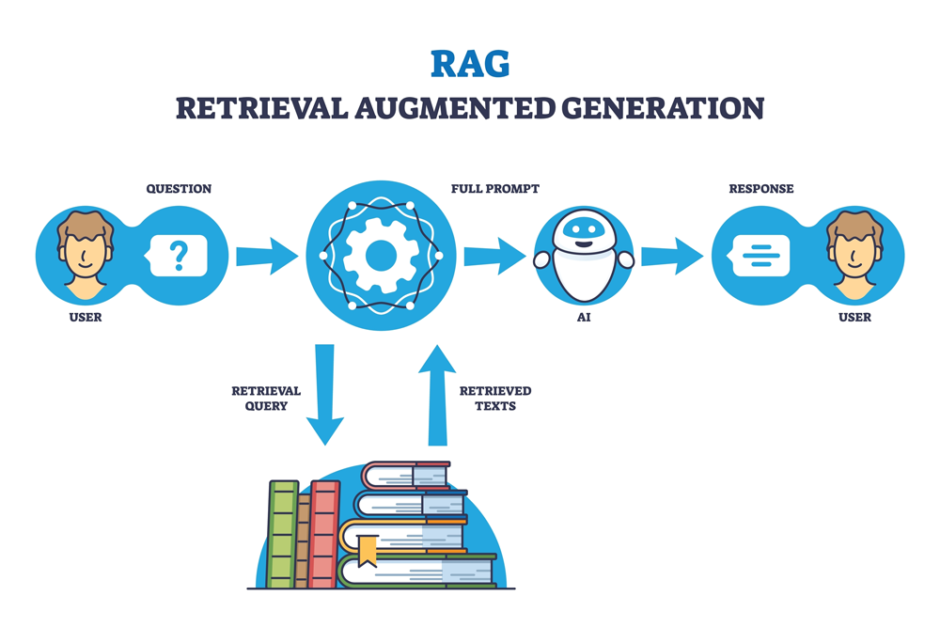
RAGは「Retrieval Augmented Generation」の略称で、日本語では「検索拡張生成」と訳されます。RAGは、外部データベースから関連情報を検索・取得し、それを基にLLM(大規模言語モデル)で回答を生成する仕組みです。
RAGとLLM(大規模言語モデル)の関係性
LLMは膨大なデータで事前学習されたモデルで、OpenAIが開発した「GPT」や、Googleが開発した「BERT」などがLLMの代表的な例として挙げられます。
LLMは、その高度な言語処理能力により多様な場面で活用されていますが、事前学習した時点より後の新しい情報や、企業固有の情報は得られないという課題があります。そこでRAGを使うことで、LLMは外部データベースから最新かつ正確な情報を取得し、より信頼性の高い回答を生成できるようになるのです。
LLMについては、「LLM(大規模言語モデル)とは?企業のDXを実現する技術の基礎知識と事例」で詳しく解説しています。
RAGと生成AIの関係性
多くの生成AIはLLMを使用しているため、前述のとおり、事前に学習させたデータの範囲内でしか回答できないという制限があります。よって最新のニュースや企業独自の情報については正確な回答ができません。多くの企業がChatGPTなどの生成AIツールの活用を進めていますが、実際の業務では、以下のような課題に悩むことがあるでしょう。
・社内の機密情報を扱えない
・業界の最新動向に対応できない
・企業独自の方針やルールを反映できない
・回答の正確性が保証できない
RAGは、こうした生成AIの課題を解決する手法として期待されています。外部の信頼できるデータベースと生成AIを組み合わせることで、企業独自の情報や最新データに基づいた、より正確な回答が可能になるからです。
このように、RAGは生成AIの「知識の期限切れ」という課題を解決し、より実用的なAIシステムの構築を可能にする技術といえます。
RAGと生成AIの違いについては、以下の記事でも詳しく解説しています。ぜひあわせてご覧ください。
株式会社WEEL|人のように「いつものアレ」を見つくろう【受注AIエージェント】
RAGとファインチューニングの違い
RAGとよく混同される言葉に、「ファインチューニング」があります。RAGとファインチューニングは、どちらも生成AIの性能を向上させる手法ですが、その技術的なアプローチが大きく異なります。
- ファインチューニング
事前学習済みの生成AIモデルに追加の学習をさせ、モデルの内部構造自体を変更する手法です。モデルに直接新しい知識を学習させることで、特定のタスクに特化した応答が可能になり、一度学習した内容は継続的に活用できます。
- RAG
一方RAGは、モデル自体は変更せずに外部の知識を活用する手法です。ユーザーから質問を受けると、まずその内容を分析し、関連する情報を外部データベースから検索します。そして、検索で得られた情報をプロンプトに組み込んで回答を生成します。
つまり、両者の本質的な違いは「知識をどこに保持するか」にあります。
ファインチューニングはモデルのパラメータ内に知識を組み込むのに対し、RAGは外部データベースに知識を置き、必要なときに参照する形をとります。そのため、RAGの場合はデータベースを更新するだけで、新たな情報を反映できる点がメリットです。
RAGの仕組み
RAGは大きく分けて「検索(Retrieval)」と「生成(Generation)」の2つのステップで動作します。まず、ユーザーの質問に関連する情報をデータベースから検索し、その結果を生成AIに渡して回答を作成します。
- 検索(Retrieval)
まず検索のステップでは、ユーザーが入力した質問を分析し、その内容に関連する情報をデータベースから探し出します。たとえば、「新製品Aの特徴は?」という質問に対しては、製品カタログや仕様書から関連する記述を検索します。この検索の精度が、最終的な回答の質を大きく左右します。
- 生成(Generation)
生成のステップでは、検索フェーズで見つけた情報を元に、LLMを使って回答を作成します。このとき、検索で得られた具体的な情報に基づいて回答するため、ハルシネーションのリスクを抑えることができます。
ハルシネーションについては、「ハルシネーションとは?生成AIを利用するリスクと対策を考える」をご覧ください。
RAGのメリット
こうした仕組みで生成AIの精度向上を実現するRAG。主なメリットをまとめると、以下のようになります。
回答の正確性・信頼性が高い
信頼できる情報源からの情報を基に回答を生成するため、誤った情報が生成されるリスクを大幅に低減できます。また、回答の根拠となる情報源も明確になるため、ファクトチェックが容易になり、情報の信頼性も高まります。
最新情報の反映が容易
RAGはファインチューニングと異なり、LLMの追加学習が不要です。そのため、データベースさえ更新すれば、例えば新製品や価格改定の情報などの変更もすぐに回答に反映できます。
社内文書やナレッジを活用できる
RAGで特定のデータベースを読み込ませることで、業務マニュアルや社内規定、過去の対応事例など、企業固有の情報を活用できます。これにより、社内特有の文脈を踏まえた的確な回答が可能になります。
RAGを実装・活用する際の課題
一方で、RAGの実装・活用時には認識しておくべき課題もあります。
システムの設計・実装が複雑
RAGは「検索」と「生成」という2つの異なる機能を組み合わせたシステムであり、その構築には高度な専門知識が必要になります。データの整理や分類、検索システムの構築、生成AIとの連携など、専門的なスキルが求められます。
そのため自社で一からRAGを構築するのが難しい場合は、専門ベンダーのサポートを受けるか、クラウドベンダーが提供する標準的なRAGソリューションを導入する形がよいでしょう。
回答に時間がかかる
RAGは質問内容に応じて、外部データベースや情報ソースを検索してから回答を生成するため、生成AIと比べて回答までに時間がかかる傾向にあります。検索対象のデータベースが大規模であったり、複雑なクエリ、同時多数のリクエストが生じる場合は注意が必要です。
パフォーマンスの改善には、検索対象データの絞り込みやインデックスの活用、ハードウェアの増強などいくつか方法があります。
回答内容がデータ品質に依存する
RAGの回答内容は、登録されているデータの質に大きく左右されます。不適切なデータが含まれていると誤った情報を提供してしまう可能性があるため、データの整理や更新は継続的に行いましょう。
RAGの具体的な活用例
最後に、実際のビジネスシーンにおいてRAGをどのように活用できるのか、具体例を交えて紹介します。
社内情報の管理
RAGを活用することで、社内規程や業務マニュアルなどの情報を一元管理し、必要な時に必要な情報を得られる仕組みを構築できます。例えば、製造業では製品仕様や製造工程の即時検索、小売業では店舗運営マニュアルや接客ガイドラインの確認など、業種を問わず幅広い場面で活用できます。新人教育や業務の引継ぎにも役立つでしょう。
カスタマーサポートの強化
カスタマーサポートにRAGを導入することで、問い合わせ対応の自動化や、オペレーターの回答支援を行えます。例えばEC事業者では、RAGにより返品や交換手続きの案内、商品情報の照会が容易になるなど、正確で一貫性のある回答の提供に役立ちます。
マーケティング活動の効率化
市場調査や競合分析など、マーケティング活動のさまざまな場面でもRAGを活用できます。例えば製造業では顧客の声の分析やトレンド把握、飲食業ではメニュー開発や立地選定のための市場調査などに役立ちます。このようにRAGを活用することで、最新のトレンドや顧客の行動データを反映した、精度の高い施策立案・実行が可能になります。
RAGの導入で生成AIの可能性が広がる
RAGは、生成AIの最大の課題である「回答の正確性」を大きく改善する技術として注目を集めています。今後、生成AIの活用がますます広がっていく中で、RAGはその精度と信頼性を支える重要な技術となるでしょう。自社の状況や目的に応じて、活用を検討してみてはいかがでしょうか。
ユーザックシステムでは、最新のRAG技術と生成AIエージェントを活用した「受注AIエージェント」のPoCサービスを提供中です。受注業務の効率化を検討されている方は、ぜひお気軽にお問い合わせください。


[…] テキストのチャンキング処理では、500文字前後の分割が効果的です。メタデータに作成日やカテゴリを付与することで、検索速度が平均47%向上します23。特殊文字の除去やフォーマット統一といった前処理が、精度向上の鍵を握ります。 […]